


Recently developed speech emotion recognition (SER) methods have placed much emphasis on the derivation of features of acoustic data. In this paper, an alternative method is described, which shows a higher accuracy of the SER implementation because it does not rely on any manual steps, such as feature extraction. The suggested approach is a mixture of Conformer blocks and CNNs which are used to predict the emotions directly based on the audio signals. The Conformer block is used to solicit long-range dependencies and time-specific features whereas CNN layers are good at extracting localized emotional information. In this design, detailed emotional content is maintained since it is otherwise overlooked due to the conventional approaches and at the same time the hierarchical depictions of emotional content are captured. The Conformer combination of time and situation data, and the CNN layers make special attention to extracting spatial features. The model was tested on three publicly available datasets and in more than one language and significantly improved accuracy and interpretability with the use of emotional and temporal information. This method moves toward affective computing since it offers a more detailed and effective analysis of the speech data.
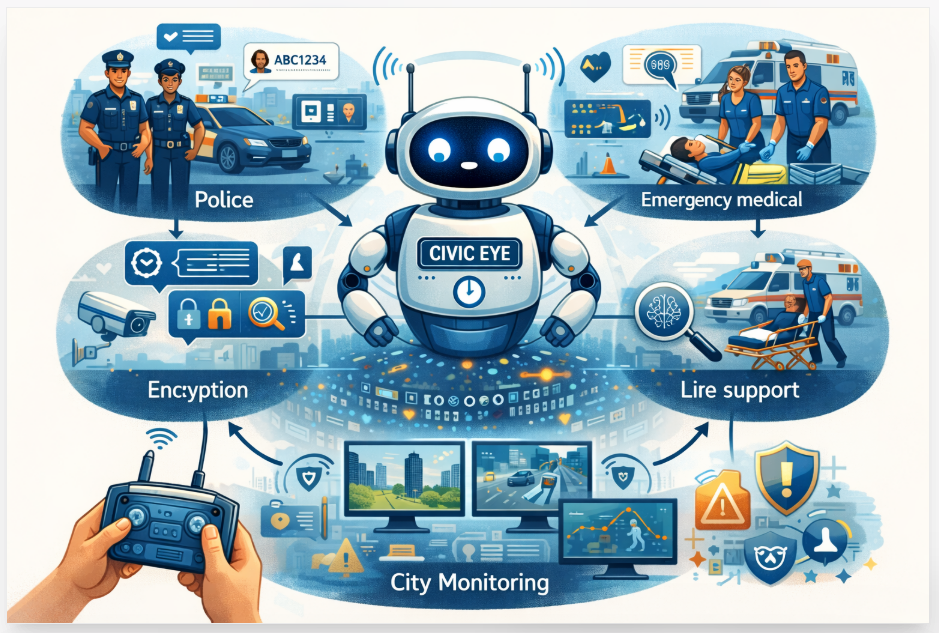
No ways rapidly rising crime rates due to digital fraud and which is limited access to real-time en...

The rapid development of 6G networks requires a communication system that can interpret and convey t...
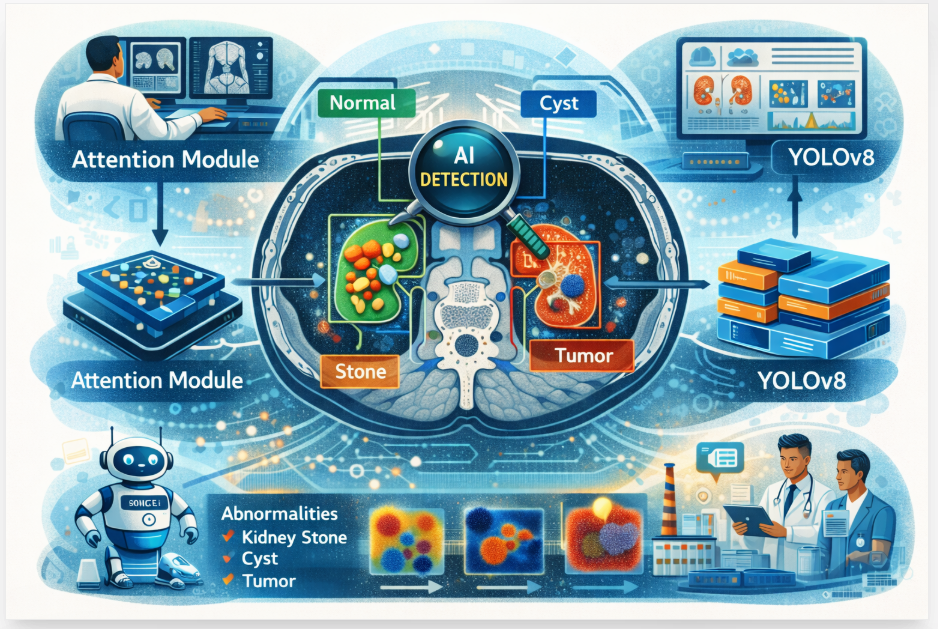
Kidney diseases such as cysts, stones, and tumors are a major global health burden, often remaining ...
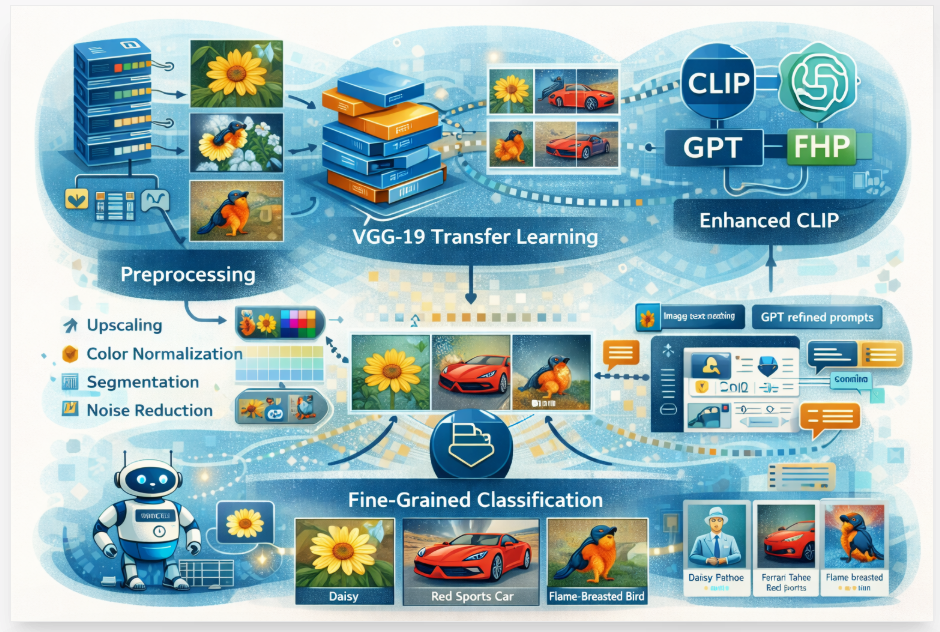
Contrastive vision-language models (VLMs) like CLIP have shown that they can do well on zero-shot cl...
