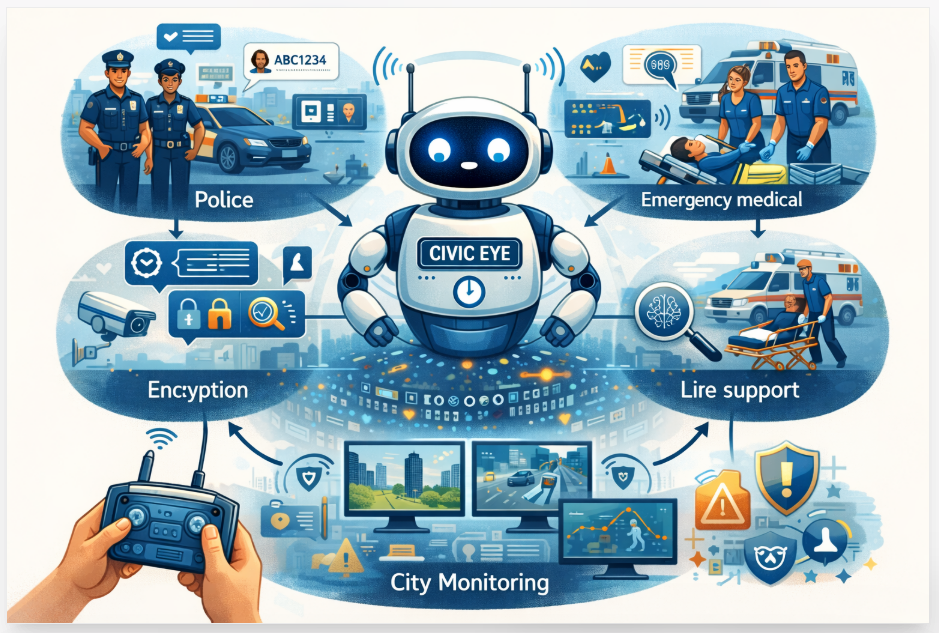
The rapid development of 6G networks requires a communication system that can interpret and convey the hidden meaning of multimodal data rather than raw signals. Semantic communication is needed because it helps systems
recognize and transmit the intended meaning of multimodal data. The current paper proposes a new model, the Advanced Multi-Modal Semantic Communication (AIMMSC) framework, for image-based semantic communication only. The suggested system relies on a hybrid ResNet-ViT architecture to detect and encode high-level visual semantics into a compact latent space, enabling resilient and efficient image communication over a low-bandwidth, noisy channel via a contrastive learning-powered semantic space with attention and transformers. AIMMSC's performance in eight key areas, including semantic accuracy, latency, robustness to noise, cross-modal alignment, adaptability, energy efficiency,
and scalability, was compared with five new semantic communication models: DeepSC, Semantic-SC, CLIP-Comm, Auto-SC, and Transformer-SC. Experimental results show that IMMSC outperforms other approaches, improving semantic correctness by 19%, robustness by 22%, and cross-modal alignment by an average of 27%. The integration of several modalities into a single latent space and the use of deep semantic encoding are the sources of these developments.
Such an approach lays the foundation for intelligent, context-aware communication. In next-generation networks, it dramatically improves the effectiveness and applicability of data interchange. For 6G applications like remote healthcare,extended reality (XR), and driverless cars, this foundation is essential.
Keywords : 6G communication, Advanced Multi-Modal, Semantic Communication, ResNet-ViT, Deep Learning.
Authors : T Venkata Krishnamoorthy , M Dharani , Ch Vijayalakshmi , N Subba Rayudu , Winny Elizabeth Philip , Sk. Rukshana Begum
Title : Advanced Multi-Modal Semantic Communication Using Hybrid ResNet-ViT Architecture for 6G Applications
Volume/Issue : 2026;3(1 (January - March))
Page No : 74 - 85